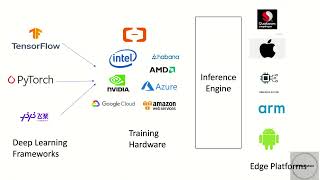
Media Summary: See the detailed reference architecture → Learn how to use JAX, Google Kubernetes Picture this: It's 3 a.m. in a bustling ER, and an This video overviews a list of popular open-source
Ai Inference Engine Cheaper With - Detailed Analysis & Overview
See the detailed reference architecture → Learn how to use JAX, Google Kubernetes Picture this: It's 3 a.m. in a bustling ER, and an This video overviews a list of popular open-source Inferact CEO and co-founder Simon Mo joins Lightspeed partners Bucky Moore and James Alcorn to break down why In this session, we talked about how Cerebras achieves high-speed