Media Summary: The content is also available as text: ... For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ... Google Cloud Developer Advocate Nikita Namjoshi introduces how
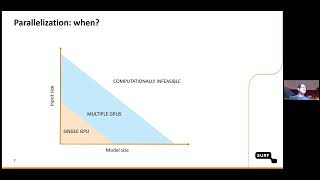
01 Distributed Training Parallelism Methods - Detailed Analysis & Overview
The content is also available as text: ... For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ... Google Cloud Developer Advocate Nikita Namjoshi introduces how A complete tutorial on how to train a model on multiple GPUs or multiple servers. I first describe the difference between Data ... Part 2 of 5 in the “5 Essential LLM Optimization Techiniques” series. Link to the 5 techiniques roadmap: ... Support this channel at: Code for animations and examples: ...
Song Han Slides: Outline: - Background and motivation - Discover how DDP harnesses multiple GPUs across machines to handle larger models and datasets, accelerating the As datasets and models grow in complexity, mastering Welcome to the lecture seven in our 'Demystifying Large Language Models' series, where we unravel the complexities of Data ...