Media Summary: Run massive AI models on your laptop! Learn the secrets of LLM quantization and how q2, q4, and q8 settings in Ollama can save ... Here's the one change that took mine from ~120 tok/s to 1200+ without a new Join Stephen Jones, one of the inventors and foremost experts in
Maximize Runtime Performance With Cuda - Detailed Analysis & Overview
Run massive AI models on your laptop! Learn the secrets of LLM quantization and how q2, q4, and q8 settings in Ollama can save ... Here's the one change that took mine from ~120 tok/s to 1200+ without a new Join Stephen Jones, one of the inventors and foremost experts in The state-of-the-art Hanlon Financial Systems Lab is the heart of the Hanlon Financial Systems Center at Stevens Institute of ... I changed 2 settings in LM Studio and I increased my t/s by about 4x. My 8gb ai In this video, we discuss how to accurately measure
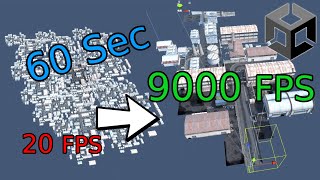
A short video on how to improve your frame rate in Unity. This video covers various optimizations to reduce draw calls such as ...