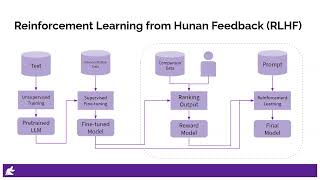
Media Summary: Want to play with the technology yourself? Explore our interactive demo → Learn more about the ... Generative Large Language Models, like ChatGPT and DeepSeek, are trained on massive text based datasets, like the entire ... Understanding Reinforcement Learning with Human Feedback (
Rlhf And Post Training Overview - Detailed Analysis & Overview
Want to play with the technology yourself? Explore our interactive demo → Learn more about the ... Generative Large Language Models, like ChatGPT and DeepSeek, are trained on massive text based datasets, like the entire ... Understanding Reinforcement Learning with Human Feedback ( Julien Launay launched Adaptive to give data science teams in business enterprises their “RLOps tooling” to make reinforcement ... As a regular normal swe, I want to share the most typical LLM This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related ...
Bunny Labs is a division of Bunny Choo Choo, a NLP-based startup focused on education. We created this course to share the ... Reinforcement Learning from human feedback, and how it's used to help train large language models like ChatGPT. Part 3 of RL ... Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... I'm far more optimistic about the state of open recipes for and knowledge of Learn how Reinforcement Learning from Human Feedback ( Want your team maximizing Claude? I run 1:1 and team AI workshops for companies doing $1M+ per year: ...