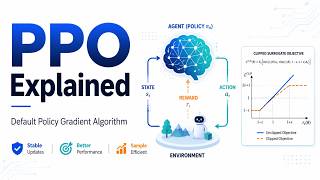
Media Summary: Reinforcement Learning from Human Feedback ( Want to play with the technology yourself? Explore our interactive demo → Learn more about the ... In this video, I break down Proximal Policy Optimization (
Visualizing Ppo Behind Rlhf - Detailed Analysis & Overview
Reinforcement Learning from Human Feedback ( Want to play with the technology yourself? Explore our interactive demo → Learn more about the ... In this video, I break down Proximal Policy Optimization ( Understanding Reinforcement Learning with Human Feedback ( In this video, I will explain Reinforcement Learning from Human Feedback ( Hands-on whiteboard session on every step of the
Generative Large Language Models, like ChatGPT and DeepSeek, are trained on massive text based datasets, like the entire ... In this episode I introduce Policy Gradient methods for Deep Reinforcement Learning. After a general overview, I dive into ... In this tutorial, we demystify one of the most important techniques for fine-tuning Large Language Models: Reinforcement ... Reinforcement Learning with Human Feedback ( This paper discusses the challenges and importance of aligning large language models (LLMs) with humans. It proposes an ...