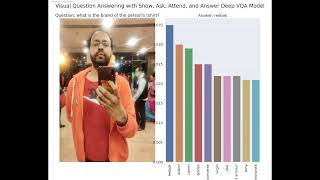
Media Summary: How to use Microsoft Phi-3 Multimodal Vision Model for Vision Mikyas Desta, Larry Chen, Tomasz Kornuta Visual Question Answering is a novel problem domain where multi-modal inputs must ... Learn how to create a system that interrogates images with
Vqa Vs Ai - Detailed Analysis & Overview
How to use Microsoft Phi-3 Multimodal Vision Model for Vision Mikyas Desta, Larry Chen, Tomasz Kornuta Visual Question Answering is a novel problem domain where multi-modal inputs must ... Learn how to create a system that interrogates images with In this work, we explore an important question in Visual Question Answering (









![[Tutorial] Local AI / VQA with Ollama, Llama Vision and Gravio](https://i.ytimg.com/vi/ex-fJhIMpiM/mqdefault.jpg)


