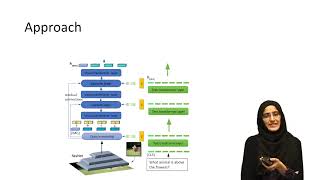
Media Summary: Authors: Pan Lu (Tsinghua University); Lei Ji (Microsoft); Wei Zhang (East China Normal University); Nan Duan (Microsoft); Ming ... Review of state-of-the-art approaches, techniques, methods and datasets for This video covers our new ICLP paper on abducing domain
R Vqa Learning Visual Relation - Detailed Analysis & Overview
Authors: Pan Lu (Tsinghua University); Lei Ji (Microsoft); Wei Zhang (East China Normal University); Nan Duan (Microsoft); Ming ... Review of state-of-the-art approaches, techniques, methods and datasets for This video covers our new ICLP paper on abducing domain Hello everyone my name is Aisha today I'm going to present our work weekly supervised grounding for Authors: Vedika Agarwal, Rakshith Shetty, Mario Fritz Description: Despite significant success in Handong Zhao, Quanfu Fan, Dan Gutfreund, Yun Fu We present a novel approach to enhance the challenging task of

![#2 Visual Question Answering (VQA) Research [Week 1]](https://i.ytimg.com/vi/xvpIuwnFu0Q/mqdefault.jpg)

![[CVPR 2020 Tutorial] Talk #2 Visual QA and Reasoning by Zhe Gan](https://i.ytimg.com/vi/n4mUriUrYR0/mqdefault.jpg)